Hello!
While I was running transform_tracking_logs command in LMS, as suggested in here, I faced some intercalated errors in event_routing_backends.tasks.dispatch_bulk_events celery tasks (see the Flower monitor screenshot below):
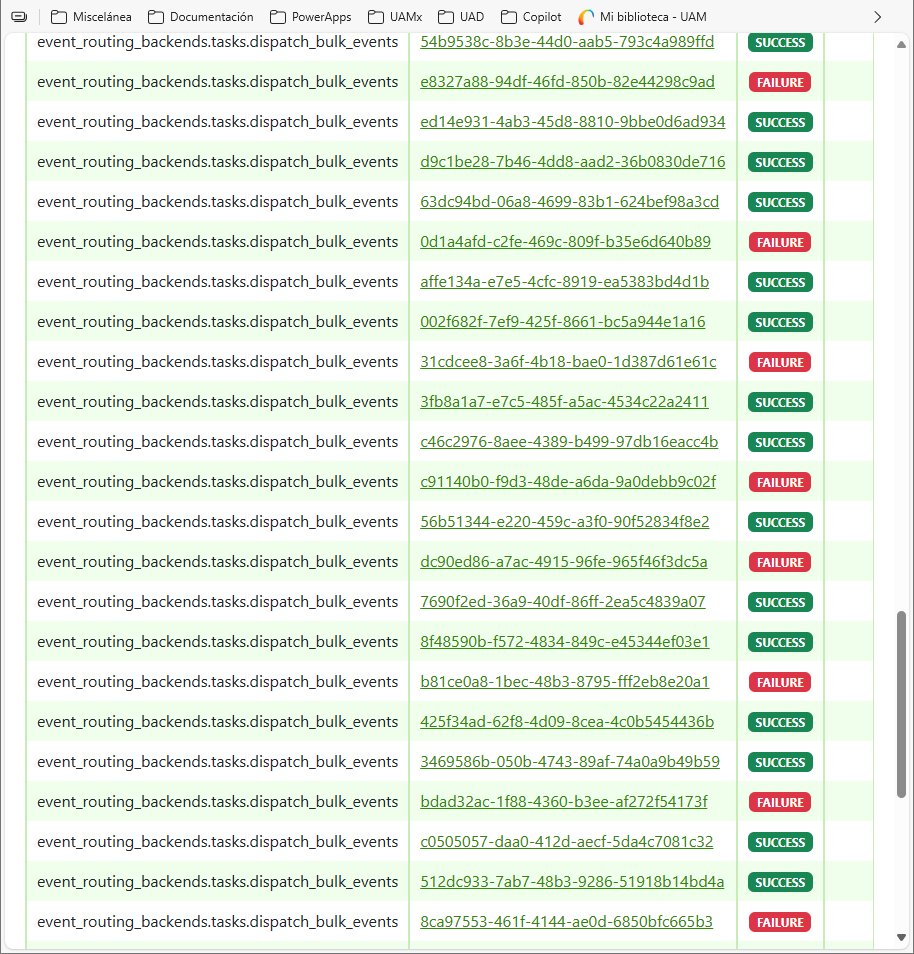
You can see the error in detail here:
Traceback (most recent call last): File "/openedx/venv/lib/python3.11/site-packages/celery/app/trace.py", line 453, in trace_task R = retval = fun(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^ File "/openedx/venv/lib/python3.11/site-packages/sentry_sdk/utils.py", line 1816, in runner return sentry_patched_function(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/openedx/venv/lib/python3.11/site-packages/sentry_sdk/integrations/celery/__init__.py", line 416, in _inner reraise(*exc_info) File "/openedx/venv/lib/python3.11/site-packages/sentry_sdk/utils.py", line 1751, in reraise raise value File "/openedx/venv/lib/python3.11/site-packages/sentry_sdk/integrations/celery/__init__.py", line 411, in _inner return f(*args, **kwargs) ^^^^^^^^^^^^^^^^^^ File "/openedx/venv/lib/python3.11/site-packages/celery/app/trace.py", line 736, in __protected_call__ return self.run(*args, **kwargs) ^^^^^^^^^^^^^^^^^^^^^^^^^ File "/openedx/venv/lib/python3.11/site-packages/event_routing_backends/tasks.py", line 106, in dispatch_bulk_events bulk_send_events(self, events, router_type, host_config) File "/openedx/venv/lib/python3.11/site-packages/event_routing_backends/tasks.py", line 147, in bulk_send_events raise task.retry(exc=exc, countdown=getattr(settings, 'EVENT_ROUTING_BACKEND_COUNTDOWN', 30), ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ File "/openedx/venv/lib/python3.11/site-packages/celery/app/task.py", line 736, in retry raise_with_context(exc) File "/openedx/venv/lib/python3.11/site-packages/event_routing_backends/tasks.py", line 127, in bulk_send_events client.bulk_send(events) File "/openedx/venv/lib/python3.11/site-packages/event_routing_backends/utils/xapi_lrs_client.py", line 103, in bulk_send raise EventNotDispatched event_routing_backends.processors.transformer_utils.exceptions.EventNotDispatched
The fact is that I need to run this command within a huge amount of data. How can I do it?
Thanks in advance!
PD: this error only applies when running the transform_tracking_logs command with a huge amount of data. When Aspects run this celery task automatically this error is never shown.